How to Run Stable Video Diffusion Locally
Official website
- github | https://github.com/Stability-AI/generative-models
- Hugging Face | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- Paper | https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
My system environment
- Memory 64G
- 3090 GPU, 24G video memory
Step one: Download
- clone official repository
git clone https://github.com/Stability-AI/generative-models
cd generative-models- Download model
There are 4 models, any one can be used, storage directory: generative-models/checkpoints
- SVD | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
Step two: Python environment configuration
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .Step three: Run
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 7862When starting, two more models will be downloaded, you can manually download and put in the following directory:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.ptDownload address:
https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/tree/main
https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.ptContinue to run, if report error
from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'add environment variable
RUN echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
source /root/.bashrcStart again successfully, you can access stable video diffusion locally: http://0.0.0.0:7862
Step four: Use
- Access local stable video diffusion http://0.0.0.0:7862
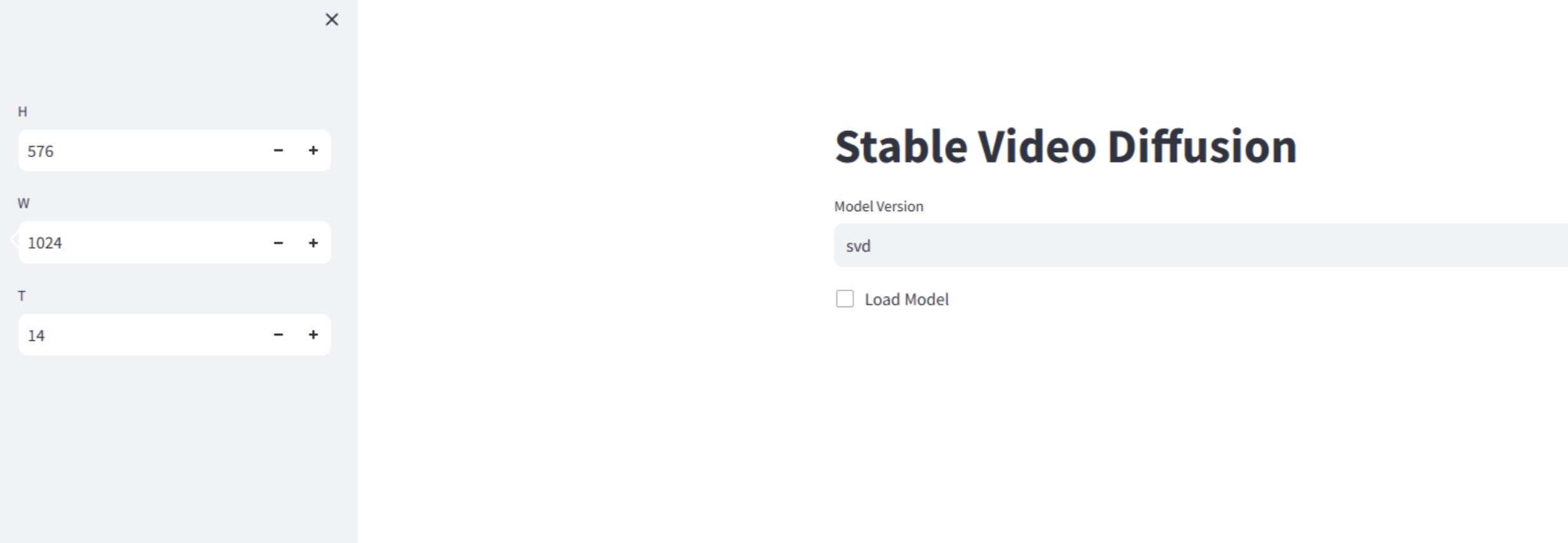
- Start operation, select model version, then check, speed depends on machine configuration, takes 2-3 minutes on our computer.
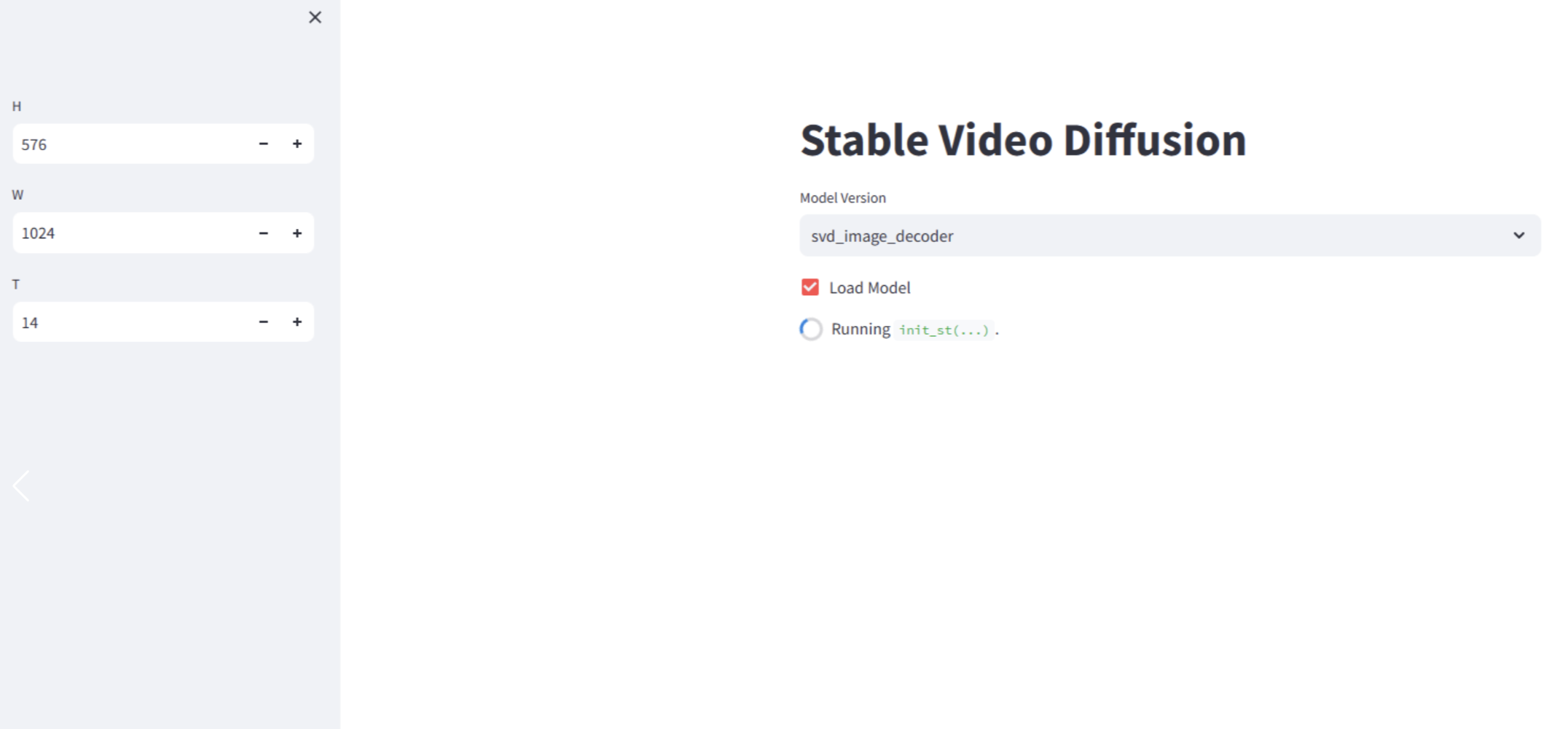
- Select image upload
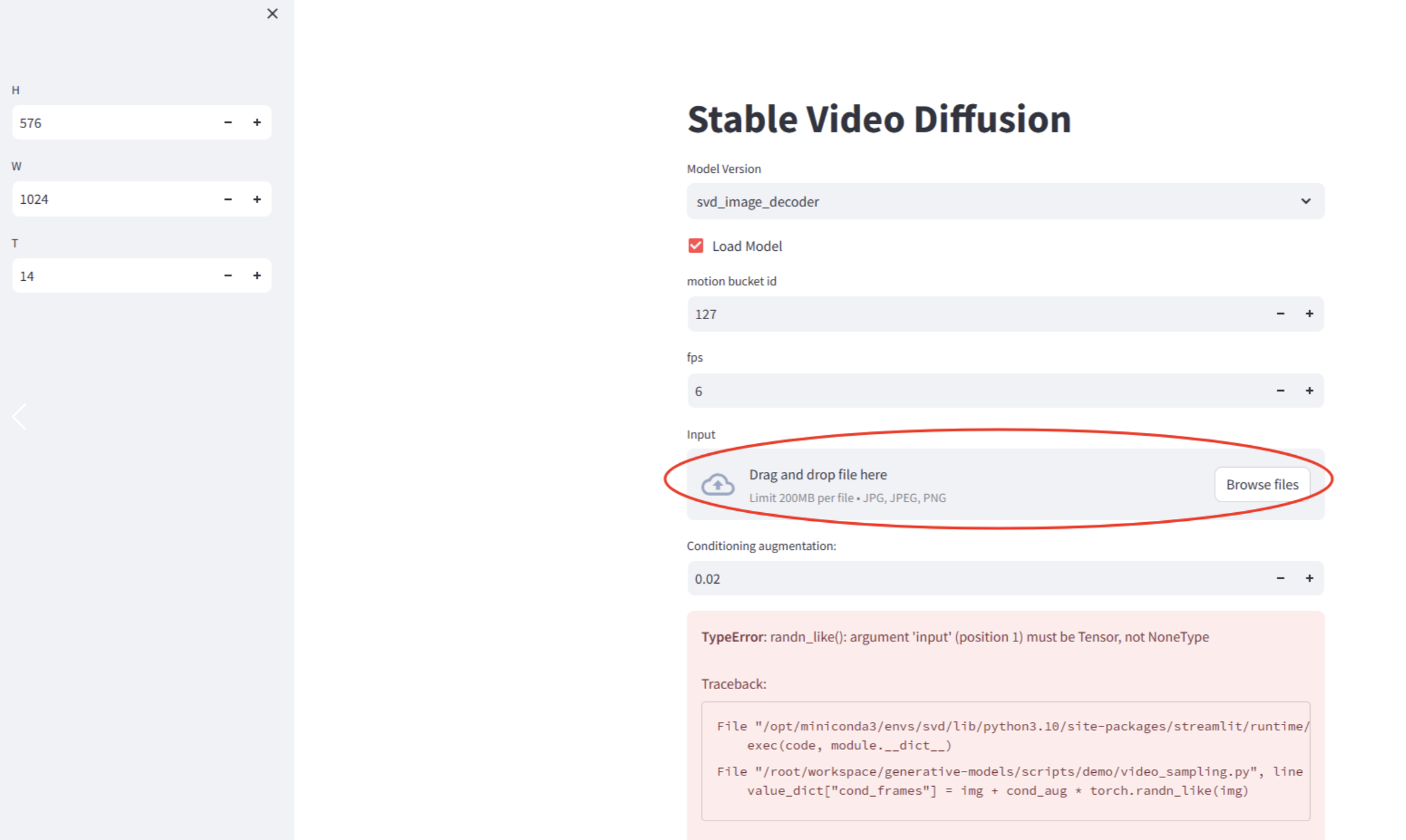
- Change the number of frames in the red box to 2, too big, memory error prone, other parameters remain unchanged. Click 'Sample', and then look backstage
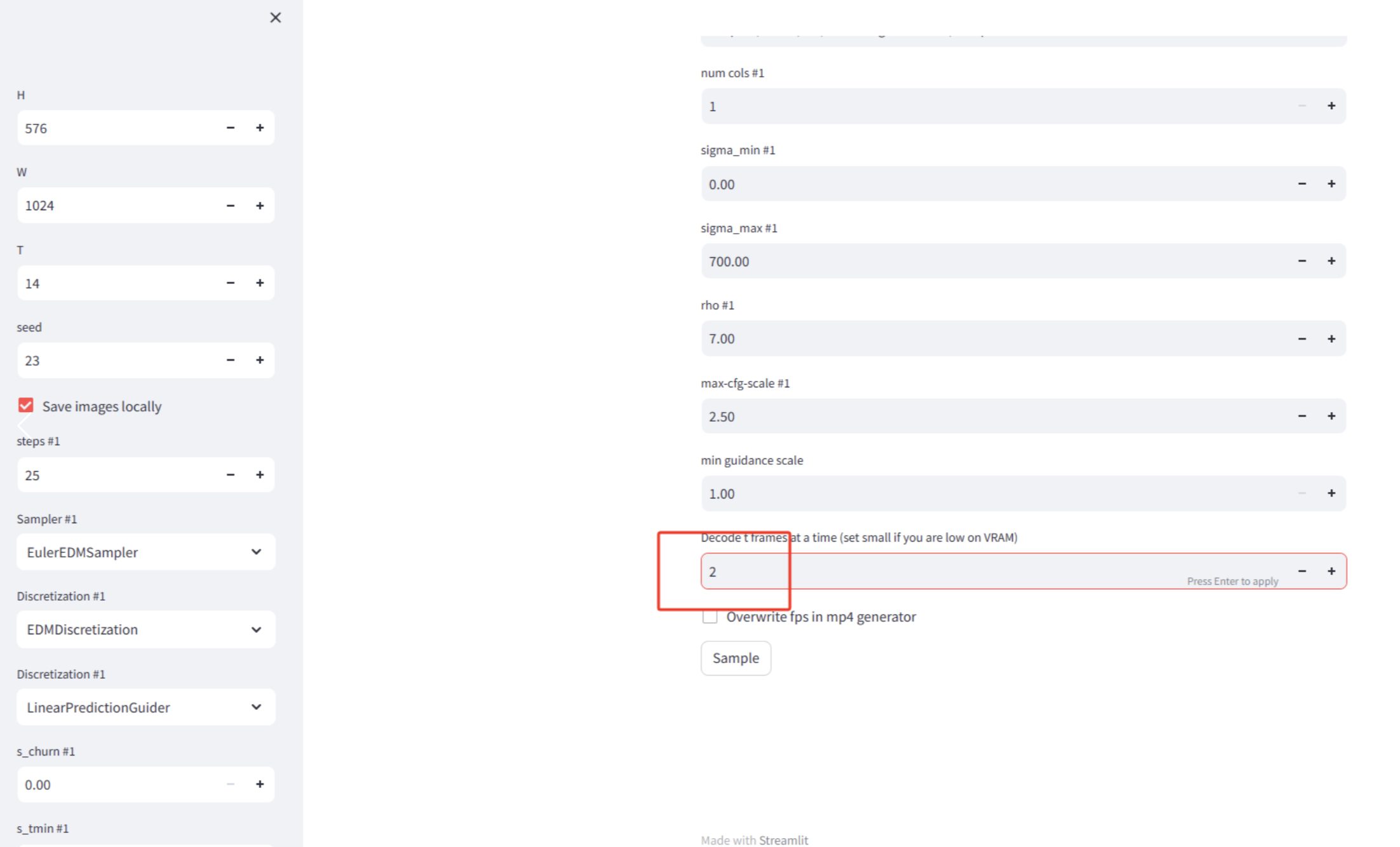
- Processing is complete, take a look at the video, the video is saved in
generative-models/outputs/demo/vid/svd_image_decoder/samples, you can see a 2 second video has been generated
